Qeexo’s AutoML enables Machine Learning and AI applications development for a range of sensors. A comprehensive list of sensors includes Accelerometer, Gyroscope, Magnetometer, Temperature, Pressure, Humidity, Microphone, Doppler Radar, Geophone, Colorimeter, Ambient light, and Proximity. In this article, we will discuss two very important configurable parameters that apply to many of these sensors, Output Data Rate (ODR) and Full-Scale Range (FSR).
Output Data Rate (ODR):
ODR (also known as “sampling rate”) is the rate at which a sensor obtains new measurements, or samples. ODR is measured in number of samples per second (Hz). Higher ODR configurations result in more samples per second. Different sensor packages often come with multiple available ODRs, and it is typically up to the application developer to determine which ODR to use based on the needs of the application.
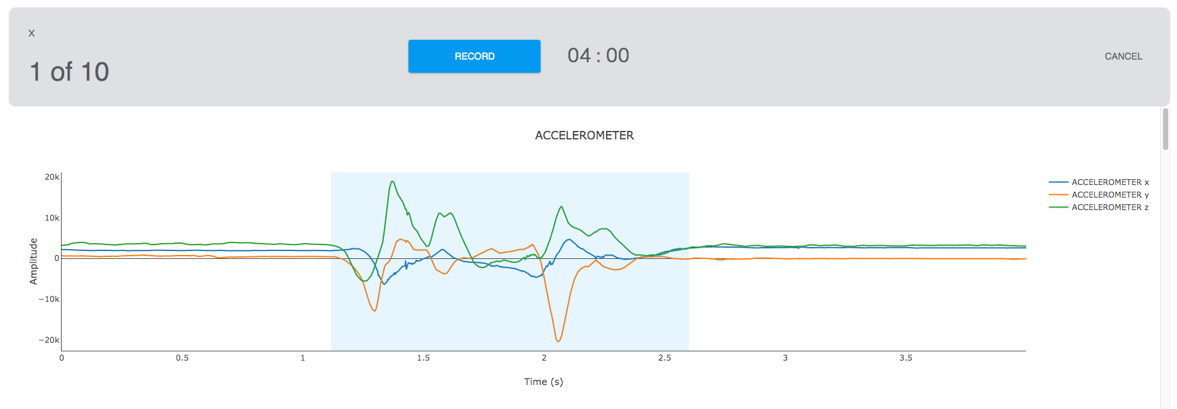
For example, accurately distinguishing between knocking and swiping on tabletop may require a higher ODR, in the range of several kHz (see Figure 1). This means that thousands of new samples are available every second, enabling the machine learning model to find the differences in rapidly changing vibration data. However, other applications such as distinguishing between walking, sitting, and running activities will likely operate very well in the range of 10-50 Hz, or tens of samples per second. Other types of scenarios, such as distinguishing between varying air gestures, fall between the previous two examples and will generally work well with ODRs in the range of 400-800 Hz.

Often, higher ODRs can improve model accuracy, since higher ODRs make more information available to the machine learning model. However, there are two major drawbacks to using higher ODR signals for embedded applications: memory constraints and power consumption.
Memory constraints need to be considered for ML models in embedded applications. On an embedded hardware platform, it is only possible to hold a relatively small number of samples in-memory, in addition to handling all of the processing required to prepare and run the machine learning model. Since this upper bound of samples is fixed, higher sensor ODRs have a lower maximum window size in terms of real time. For example, if a given hardware platform can only hold 1000 samples in memory at any given time, this represents approximately 2.5 seconds of 400 Hz data, while it only represents 1/3 of a second of 3.3 kHz data.
Power consumption also needs to be considered for embedded applications and will be higher for higher sampling rates. Generally, running machine learning on embedded devices means striking a good balance between performance of the machine learning algorithms and meeting power consumption constraints for the embedded application. This is an especially important consideration for models which will be deployed to devices running only on battery power. It is recommended to try building models with a few different ODRs and check the performance of the models.
Qeexo AutoML can build ML applications for all the available ODRs of sensors included in the supported hardware platforms. Accelerometers and gyroscopes generally have many different ODR options. Some industrial grade accelerometers can have ODRs as high as 26KHz, e.g., ~=26000 samples in one second. These accelerometers are capable of operating in industrial environments and are a great fit for machine monitoring applications on Qeexo AutoML.
Number of samples per second can vary depending on the hardware and firmware properties of the sensor module. Qeexo AutoML performs data quality checks, where it tests that the effective ODR matches the configured ODR of the sensors, among other things. We also recommend using Qeexo AutoML’s visualization tool to visually check the signal before training the ML models.
Full Scale Range (FSR):
Full Scale Range is associated with the range of values that can be measured for a given sensor and allows the application developer to trade-off measurement precision for larger ranges of detection. Two sensors that often have variable FSR settings are accelerometers and gyroscopes. Accelerometers measure the acceleration (rate of change of velocity of an object) in X, Y, and Z directions in the units of g (relative to the force of gravity). Gyroscopes measure angular velocity in Degrees per Second (DPS) in X, Y, and Z rotational directions.
Full scale range for accelerometers is generally programmable as ±2/±4/±8/±16 g, depending on the hardware platform. The smaller the range, the more sensitive the accelerometer will be to lower amplitude signals. For example, to measure small vibrations on a tabletop, using a FSR of 2g would provide more detailed data as it will be very sensitive to any minor accelerations, whereas using a 16g range might be more suitable to measure vibrations of somebody walking.
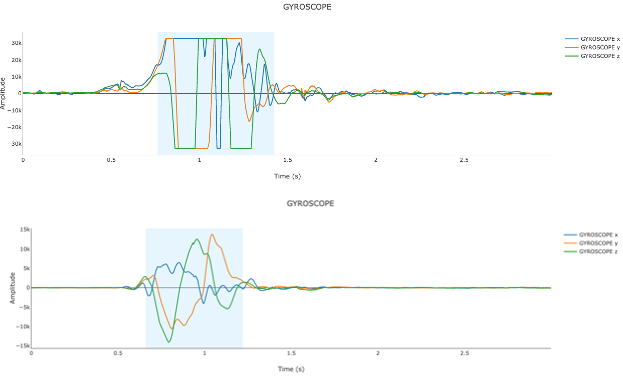
The DPS range for gyroscopes is generally programmable to ±125/±250/±500/±1000/±2000 depending on the hardware platform. The smaller the DPS range, the more sensitive the gyroscope will be to smaller angular motions. For example, to measure small angular motions for hand gestures used in a gaming application, using a smaller range would provide more detailed angular velocity data than using a 2000 DPS range, which might be more suitable to measure the angular motion of a fan.
It is recommended to check for saturation of signals while working with FSR. If lower g and DPS are configured for accelerometer and gyroscope, but their actual measurements are higher than the configuration, their signals will saturate. Saturation happens because they cannot measure the desired physical quantities greater than their configuration, which would result in overflow. We recommend using Qeexo AutoML’s visualization tool to check for the saturation of the signals. Qeexo AutoML’s data quality check also checks for signal saturation and warns users when saturation is suspected.