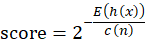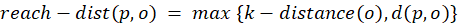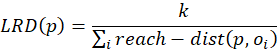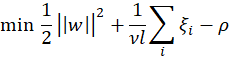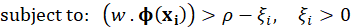This blog post is a companion to my talk at tinyML Summit 2021. The talk and this blog overlap in some content areas, but each also has unique content that complements the other. Please check out the video if you are interested.
Why Quantization?
For embedded applications, size matters. Compared to CPUs, embedded chips are much more constrained in various ways: in memory, computation ability, and power. Therefore, small models are not just desirable, they are essential. We at Qeexo have asked ourselves: how can we make small, high-performance models? We have dedicated resources to answering this question, and we have made advances in compressing many of our model types. For some of those model types, compression has been achieved through quantization.
For our purposes here, the following is what we mean when we “quantize” a machine learning model:
Change the data types used to encode the trained-model parameters from larger-byte data types to smaller-byte data types, while retaining the behavior of the trained model as much as possible.
By using smaller-byte data types in place of larger-byte data types, the quantized machine learning model will require fewer bytes for its encoding and will therefore be smaller than the original.
Why Tree Models?
In our experience at Qeexo we have found that tree-based models often outperform all other model types when the models are constrained to be small in size (e.g. < 100s KB) or when there is relatively little available data (e.g. < 100,000 training examples). Both of these conditions are often true for machine learning problems targeting embedded devices.
Memory constraints on embedded devices
As stated above, due to the memory constraints on the device the models must be small. For example, the Arduino Nano 33 BLE Sense has 1 MB CPU flash memory and 256 KB SRAM. These resources are shared among all programs running on the device, and the available resources for a machine learning model are going to be significantly smaller than the full amounts. The actual resources available for the machine learning model will vary by use-case, but a reasonable estimate as a starting point is that perhaps half of the resources can be used by the machine learning model.
Available data for embedded machine learning applications
As for the amount of available data, several factors tend to lead to relatively little available data
for machine learning models targeting embedded devices:
- To train a machine learning model that is to be used on a given embedded platform, the training data must be collected from that platform. Large datasets collected from embedded platforms are not generally available online.
- The organization that wishes to produce the machine learning model must usually collect the data on its own. This is costly in time and effort.
- Machine learning applications usually require specialized training data. This means that a data collection effort usually needs to be performed for each problem that is to be solved.
Because tree-based models tend to perform well, and are often the superior model type, under the constraints above, they are well-suited for embedded devices. For this reason, we are interested in using them for our own embedded applications and in offering them as part of our suite of models for use in Qeexo AutoML.
Tree Model Quantization
Encodings of trained tree-based models lead to parameters and data that fall into 3 categories:
- Leaf values: these are the values that carry the information about which class or regression value is the prediction for the instance in question during inference.
- Feature threshold values at the branch nodes: these values determine how an instance traverses the tree during inference, and eventually which leaf is reached in the end.
- The tree structure itself: this is the information encoding how the various nodes of the tree connect to each other.
The first two categories above, leaf values and feature thresholds, provide the possibility for quantization. At Qeexo, we have implemented quantization for these parameter types. While there has been research on and implementations for quantization of neural-network-based models, we aren’t aware of similar research and implementations for tree-based models; we have done our own research and created an implementation for quantization for tree-based models.
Quantization Gains and Costs
Our main gain for quantizing tree-based models: model compression
In our experience, the strongest constraint placed on tree models by embedded chips is the flash size. By quantizing the model, the number of bytes needed to encode the model is smaller. This allows tree-based models to fit on the device that would not have fit without quantization, or in the case of smaller tree-based models, quantizing them leads to more room on the embedded device for other functionality.
The main cost for quantizing tree-based models: loss of model fidelity
Reducing the size of the data types used to encode the trained model parameters leads to some loss of information for those parameters, and this leads to a difference in behavior between the original model and the quantized version. The difference in behavior is often small, but if it is not small enough it can sometimes be made smaller by giving up some compression gains (i.e. increase the size of the quantized data type; in the “Leaf Quantization Example” below, one could use the 2-byte uint16 instead of the 1-byte uint8 as the quantized data type. This would make the quantized model more faithful, but also bigger).
There is another factor that can lead to a reduction in compression gains when quantizing tree-based models: depending on the tree model in question and on the quantization type, it may be necessary to store some of the parameters of the quantization transformation along with the model on-device. This is because in some cases it is necessary to de-quantize one or more quantized parameters during inference to correctly produce predictions or prediction probabilities. Storing these transformation parameters costs bytes on-device, which eats into the compression gains. The number of transformation parameters required depends strongly on the quantization type. For example, when using a simple quantization scheme such as an affine transformation (a shift followed by a rescaling), the leaf quantization transformation parameters are 2 floating-point parameters if all leaf values are quantized together. On the other hand, for feature threshold quantization, each feature used in the model requires a stored transformation, which leads to 2 floating-point parameters per used feature. The former costs very little (a few bytes), and is applicable to any tree implementation with floating-point leaf values or integer leaf values when the values are large enough. The latter can cost many bytes depending on the number of features, and should only be considered for large models where the number of splits per feature across the tree-based model is large enough to absorb the cost of storing the feature threshold quantization parameters.
Leaf Quantization Example
To illustrate the gains and costs of tree model quantization, we’ll consider an example using leaf quantization. For our example, consider a “letter gesture” problem, a benchmark problem we use often at Qeexo. The setup:
- Arduino Nano BLE Sense, held in the hand
- Accelerometer and gyroscope sensors active
- 4 classes of letter gestures, traced out in the air: A, O, S, V
- 1 class of no gesture
- Qeexo AutoML accelerometer and gyroscope feature stack used for the features
- Data after featurization: approximately 300 examples for each letter gesture, and 1500 examples for the no-gesture case
- Train/test split: approximately 2/3 of the data is used for training, 1/3 as the test set
- Model:
sklearn.ensemble.GradientBoostingClassifierwith default parameters (mostly)
The Un-Quantized Model
- Overall accuracy on the held-out test set: 96.1% (927/965)
- Confusion matrix:
| true/pred | A | NOISE | O | S | V |
|---|---|---|---|---|---|
| A | 133 | 0 | 2 | 0 | 2 |
| NOISE | 0 | 543 | 0 | 0 | 0 |
| O | 0 | 0 | 98 | 1 | 0 |
| S | 3 | 1 | 21 | 95 | 0 |
| V | 8 | 0 | 0 | 0 | 58 |
- The model performs pretty well. The most difficult class for the model to classify correctly is ‘S’, which is at times classified as ‘O’
- Bytes to encode the model and the breakdown into categories:
| Value | Number | Encoding | Bytes |
|---|---|---|---|
| Leaves | 3595 | float32 | 14380 |
| Feature Thresholds | 3095 | float32 | 12380 |
| Tree Structure | various uint | 12884 | |
| Total | 39644 |
The breakdown in bytes will generally follow this pattern, with the leaves and feature thresholds making up about 1/3 of the total model size each (with leaves always a bit more; for each tree there is always one more leaf than the number of splits), with the tree structure making up the remaining 1/3.
To quantize the model, we need to choose what parameters to quantize and the quantization transformation. For this example, we are quantizing the leaves only, and let us quantize them via an affine transformation (a shift followed by a rescaling) down to 1-byte uint8 values. With this transformation, we will reduce the bytes required to encode the leaves by a factor of 4. For this tree implementation, we do need to retain one of the leaf quantization parameters on-device for use during inference, but this costs very little: a single 4-byte float32. This value is used to rescale the accumulated leaf values back into the un-quantized space before applying the softmax function to compute the by-class probabilities.
The Quantized Model
- Overall accuracy on the held-out test set: 95.8% (924/965)
- Confusion matrix:
| true/pred | A | NOISE | O | S | V |
|---|---|---|---|---|---|
| A | 133 | 0 | 2 | 0 | 2 |
| NOISE | 0 | 543 | 0 | 0 | 0 |
| O | 0 | 0 | 98 | 1 | 0 |
| S | 3 | 1 | 24 | 92 | 0 |
| V | 8 | 0 | 0 | 0 | 58 |
- Bytes to encode the model and the breakdown into categories:
| Value | Number | Encoding | Bytes |
|---|---|---|---|
| Leaves | 3595 | uint8 | 3595 |
| Feature Thresholds | 3095 | float32 | 12380 |
| Tree Structure | various uint | 12884 | |
| Leaf quant params | 1 | float32 | 4 |
| Total | 28863 |
Consequences of Quantization
- Checking the test example predictions shows that the only difference in the predictions is that the quantized model mis-classifies 3 previously-correct ‘S’ examples as ‘O’.
- All 3 examples which were predicted differently are borderline cases for which the un-quantized model was already fairly confused.
- The changes in probabilities between the two models is very small, with the maximum absolute difference in probabilities (across all test examples and classes) being about 0.013.
- The multi log loss (computed via
sklearn.metrics.log_loss) has increased a small amount: from 0.0996 for the un-quantized model to 0.0998 for the quantized model. - The number of bytes necessary to encode model parameters has been reduced by 27%.
The quantization procedure effectively introduces some small amount of noise into the model parameters. We expect that this will on average degrade performance, and this is seen here in this particular example: quantizing the model led to slightly lower performance on the held-out data.
So, at the cost of a slight loss in model fidelity we have reduced the overall model size by 27%. The trade-off observed in this example matches our experience at Qeexo with quantized models generally: a slight loss in fidelity with a significant reduction in model size. In the context of an embedded device, this amount of reduction is often a worthwhile trade-off.
Conclusion
In this post, we have discussed why compressed tree-based models are useful models to consider for embedded machine learning applications, and have focused on a particular compression technique: quantization. Quantization can compress models by significant amounts with a trade-off of slight loss in model fidelity, allowing more room on the device for other programs.
The quantized tree-based models are among the model types available for use in Qeexo AutoML, an end-to-end automated machine learning pipeline targeting embedded devices. To learn more and try out Qeexo AutoML for free, head to https://qeexotdkcom.wpengine.com/ml-platform/.

















 . This results in the initial sensitivity value of
. This results in the initial sensitivity value of  for each class represented as
for each class represented as  such that
such that![\[ \sum _{i=1}^{C}s_i = 1\ \]](https://qeexo.tdk.com/wp-content/ql-cache/quicklatex.com-d28b4371b3c248c6fae4c4b327d610d1_l3.png "Rendered by QuickLaTeX.com")
 = 0.5, 0.5. If we start lowering one of the numbers, the model becomes more sensitive to that particular class. Lowering the sensitivity number of particular class is equivalent to increasing the weight of that class. All the model performance metrics such as Confusion matrix, Learning Curves, ROC curves, F-1 Score, and MCC are all computed with the default sensitivity value
= 0.5, 0.5. If we start lowering one of the numbers, the model becomes more sensitive to that particular class. Lowering the sensitivity number of particular class is equivalent to increasing the weight of that class. All the model performance metrics such as Confusion matrix, Learning Curves, ROC curves, F-1 Score, and MCC are all computed with the default sensitivity value 

![\[ y= \begin{dcases} class_1, & \text{if} P(class_1) > 0.5\\ class_0, & \text{otherwise} \end{dcases} \]](https://qeexo.tdk.com/wp-content/ql-cache/quicklatex.com-0b8d18a1a4d61bdd55a59ef21931d91a_l3.png "Rendered by QuickLaTeX.com")
![\[ y= \begin{dcases} class_1, & \text{if} P(class_1) > 0.75\\ class_0, & \text{otherwise} \end{dcases} \]](https://qeexo.tdk.com/wp-content/ql-cache/quicklatex.com-8ced2c8d2e82652aecf0b75f33ff8cdc_l3.png "Rendered by QuickLaTeX.com")
 , otherwise we want to classify the incoming signal (or pattern) into class-0. With this classification rule, the model remains the same but becomes more sensitive to one class over the other(s). In order to achieve this classification rule, the weights are computed as given below:
, otherwise we want to classify the incoming signal (or pattern) into class-0. With this classification rule, the model remains the same but becomes more sensitive to one class over the other(s). In order to achieve this classification rule, the weights are computed as given below:
![\begin{align*} weighted\_probability= [2, 0.67] * [0.4, 0.6] = [0.80, 0.40] \end{align*}](https://qeexo.tdk.com/wp-content/ql-cache/quicklatex.com-0f264a42eb0b43bf2595f1a179458f10_l3.png "Rendered by QuickLaTeX.com")
![\begin{align*} normalized\_weighted\_probability= [0.80/(0.8 + 0.40), 0.40/(0.80 + 0.40)] = [0.666, 0.333] \end{align*}](https://qeexo.tdk.com/wp-content/ql-cache/quicklatex.com-1775fe4398225f68aa334dec12cea7e3_l3.png "Rendered by QuickLaTeX.com")